大模型推理原理
什么是大语言模型推理
大语言模型(LLM)推理是指给定输入文本(Prompt),模型通过自注意力机制和概率分布预测下一个 token,生成输出文本的过程。
推理流程
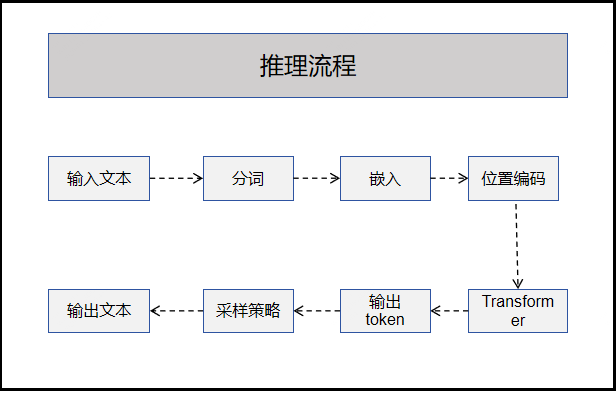
各阶段说明
| 阶段 | 输入 | 输出 | 说明 |
|---|---|---|---|
| 分词 | 文本 | token ID 序列 | 将文本切分为模型可处理的最小单元 |
| 嵌入 | token ID | 向量 | 将 token 映射为高维向量表示 |
| 位置编码 | 向量 | 添加位置信息 | 让模型感知token位置关系 |
| Transformer | 向量序列 | 隐藏状态 | 核心计算,多层自注意力 |
| 词汇投影 | 隐藏状态 | 词汇概率分布 | 预测下一个 token |
| 采样 | 概率分布 | token ID | 根据策略选择输出 token |
| 反分词 | token ID | 文本 | 将 token 序列还原为文本 |
核心技术组件
1. 分词器 (Tokenizer)
分词器将文本转换为模型可以处理的 token 序列。
中文分词示例:
输入: "今天天气很好"
输出: [192, 3847, 2093, 3847, 452, 2398] # 6 个 tokens英文分词示例:
输入: "hello world"
输出: [15339, 1917] # 2 个 tokens2. 自注意力机制 (Self-Attention)
自注意力是 Transformer 的核心,让模型能够"看到"文本中任意位置之间的关联:
Query (查询): "我想去"
Key (键): "北京天气"
Value (值): "北京温度信息"
注意力分数 = softmax(Q × K^T / √d)3. 采样策略
| 策略 | 说明 | 适用场景 |
|---|---|---|
| Greedy | 选择概率最高的 token | 确定性输出 |
| Temperature | 通过温度控制随机性 | 创意写作 |
| Top-p | 从累积概率 p 的集合中采样 | 平衡质量与多样性 |
温度参数效果:
| 温度值 | 效果 |
|---|---|
| T < 1.0 | 更确定、更保守 |
| T = 1.0 | 平衡 |
| T > 1.0 | 更随机、更创意 |
推理效率优化
KV Cache
缓存已计算的 Key 和 Value,避免重复计算:
无 KV Cache: 每次生成都重新计算所有历史 token
有 KV Cache: 只需计算新 token 的 KV,复用历史批处理 (Batching)
同时处理多个请求,提高 GPU 利用率:
单请求: [用户1的输入]
批处理: [用户1, 用户2, 用户3, ...] 的输入量化 (Quantization)
使用低精度(如 INT8)减少内存占用:
| 精度 | 内存占用 | 质量损失 |
|---|---|---|
| FP32 | 100% | 无 |
| FP16 | 50% | 极小 |
| INT8 | 25% | 可接受 |
| INT4 | 12.5% | 取决于任务 |
平台优化策略
天枢AI-TokenHub 通过以下方式提供高效推理:
- 智能路由: 自动选择最优模型和节点
- 分布式推理: 大请求多节点协作
- 缓存复用: 相同请求返回缓存结果
- 流量调度: 削峰填谷平衡负载