LLM Inference Principles
What is LLM Inference
LLM (Large Language Model) inference refers to the process where, given an input text (Prompt), the model predicts the next token through self-attention mechanisms and probability distribution, generating output text.
Inference Flow
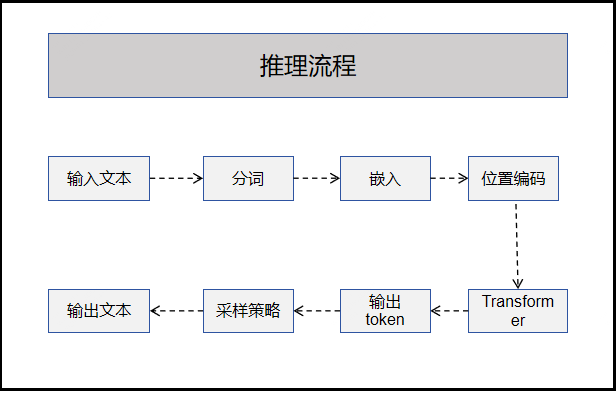
Stage Descriptions
| Stage | Input | Output | Description |
|---|---|---|---|
| Tokenize | Text | token ID sequence | Split text into model-processable units |
| Embed | token ID | Vector | Map token to high-dimensional vector |
| Positional Encoding | Vector | Position info added | Let model perceive token position relationships |
| Transformer | Vector sequence | Hidden states | Core computation, multi-layer self-attention |
| Vocabulary Projection | Hidden states | Vocabulary probability | Predict next token |
| Sampling | Probability distribution | token ID | Select output token based on strategy |
| Detokenize | token ID | Text | Convert token sequence back to text |
Core Technical Components
1. Tokenizer
Tokenizer converts text into token sequences that the model can process.
Chinese Tokenization Example:
Input: "今天天气很好"
Output: [192, 3847, 2093, 3847, 452, 2398] # 6 tokensEnglish Tokenization Example:
Input: "hello world"
Output: [15339, 1917] # 2 tokens2. Self-Attention
Self-attention is the core of Transformer, enabling the model to "see" relationships between any positions in the text:
Query: "I want to go"
Key: "Beijing weather"
Value: "Beijing temperature info"
Attention score = softmax(Q × K^T / √d)3. Sampling Strategies
| Strategy | Description | Use Case |
|---|---|---|
| Greedy | Select token with highest probability | Deterministic output |
| Temperature | Control randomness via temperature | Creative writing |
| Top-p | Sample from set with cumulative probability p | Balance quality and diversity |
Temperature Effects:
| Temperature | Effect |
|---|---|
| T < 1.0 | More deterministic, conservative |
| T = 1.0 | Balanced |
| T > 1.0 | More random, creative |
Inference Efficiency Optimization
KV Cache
Cache computed Key and Value to avoid redundant calculations:
Without KV Cache: Recalculate all historical tokens for each generation
With KV Cache: Only compute KV for new tokens, reuse historyBatching
Process multiple requests simultaneously to improve GPU utilization:
Single request: [User 1's input]
Batching: [User 1, User 2, User 3, ...] inputsQuantization
Use lower precision (e.g., INT8) to reduce memory usage:
| Precision | Memory | Quality Loss |
|---|---|---|
| FP32 | 100% | None |
| FP16 | 50% | Minimal |
| INT8 | 25% | Acceptable |
| INT4 | 12.5% | Task-dependent |
Platform Optimization Strategies
AI-TokenHub provides efficient inference through:
- Smart Routing: Automatically select optimal model and node
- Distributed Inference: Multi-node collaboration for large requests
- Cache Reuse: Return cached results for identical requests
- Traffic Scheduling: Balance load through peak-shaving